为什么validation loss > train loss
查看代码histroy/log/writer中是否将二者搞反了。
Regularization/正则化
在训练集中使用了正则化,但是验证、测试集中没有。
验证或者测试时会使用,model.eval(),会冻结Batchnorm等正则化层。
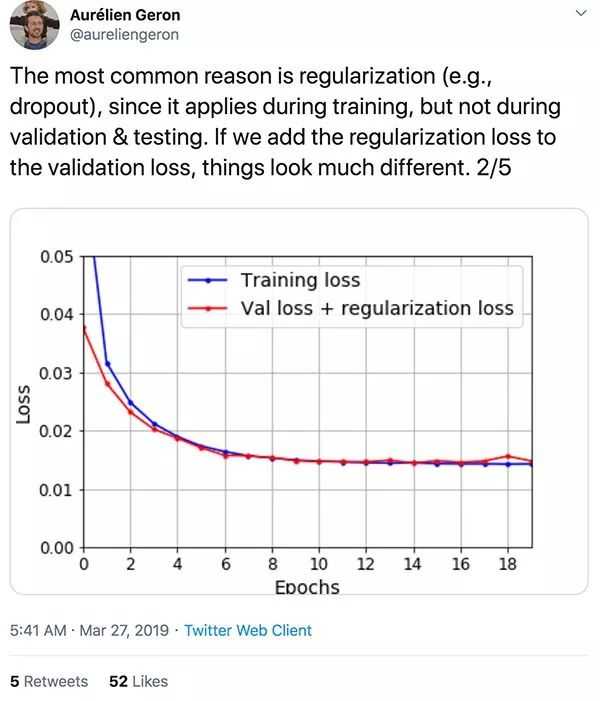
Note: 训练深度神经网络时,常常应用正则化来获得更好的验证、测试精度;理想情况下还可以更好的泛化新的数据。但是正则化方法往往会牺牲训练准确度,在某些情况下回导致验证loss低于训练loss。
可能的正则化方法:
- Dropout: 表现为验证损失始终低于训练损失,它们之间的差距或多或少保持相同大小,并且训练损失有波动。Dropout 通过在模型训练期间随机冻结层中的神经元来惩罚模型方差。与 L1 和 L2 正则化一样,dropout 只适用于训练过程,会影响训练损失,导致验证损失低于训练损失的情况。
- L2权重衰减: 表现为验证损失始终低于训练损失,但他们之间的差距随着时间的推移而缩小。训练 loss 和验证 loss 的差距会随着训练次数增加而减小,这是因为网络在学习减小正则项。但是网络实际上还是在训练集上表现的更好。
- 减少模型容量,使用更浅的模型
因此如果遇到了validation loss低于train loss时,可能是模型over-regularized,可以通过如下方法放宽正则化约束:
- 降低L2权重衰减强度
- 减少dropout数量
- 增加模型容量(深度)
巧合验证集比训练集更容易

可能的改进和思考方向:
- 同分布采样
- 确保难度一致
- “数据泄露leakage”,即训练样本与验证、测试样本意外混入
train loss 不断下降,test loss不断下降,说明网络仍在学习;
train loss 不断下降,test loss趋于不变,说明网络过拟合;
train loss 趋于不变,test loss不断下降,说明数据集100%有问题;
train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;
train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。
Comments NOTHING