安装
在Ubuntu系统安装Python 3
Ubuntu may ship with Python 3, as the default Python installation. 如果没有则需要安装。
安装pip3
Complete the following steps to install pip (pip3) for Python 3:
- Start by updating the package list using the following command:
sudo apt update - Use the following command to install pip for Python 3:
sudo apt install python3-pipThe command above will also install all the dependencies required for building Python modules.
- Once the installation is complete, verify the installation by checking the pip version:
pip3 --version
安装PyFoam
sudo apt-get install gnuplot gnuplot-x11 #安装Gnuplot
pip3 install PyFoam # 安装PyFoam
在终端中将默认运行环境切换到Python 3
update-alternatives --remove python /usr/bin/python2
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 10
以上命令移除Python 2并将Python 3的优先级设为10.
测试安装是否成功:
pyFoamListCases.py
若安装成功且当前目录没有OpenFOAM案例,则返回No cases found。
或者使用pyFoamVersion.py测试安装成功与否。
安装swak4foam
安装mercurial
sudo apt install mercurial
下载swak4foam
hg clone http://hg.code.sf.net/p/openfoam-extend/swak4Foam swak4Foam
#Go into swak4Foam's main source folder
cd swak4Foam
# This next command will take a while...
./Allwmake
#Run it a second time for getting a summary of the installation
./Allwmake > log.make 2>&1
测试swak4Foam是否安装成功:
funkySetFields
安装文本编辑器Emacs
2023-04-07 How to Install Emacs Editor in Ubuntu 20.04 – LinuxWays
PyFoam使用
pyFoamCloneCase.py
pyFoamCloneCase.py $FOAM_TUTORIALS/heatTransfer/buoyantPimpleFoam/hotRoom 01baseCase
cd 01baseCase
ls
rm All*
mv 0 0.org
cat PyFoamHistory
pyFoamPrepareCase.py
pyFoamPrepareCase.py is a utility to set up cases in a reproducible way:

There are two versions of a training presentation on this
- One with cats https://bit.ly/pyFPrepCats and Alternate URL https://openfoamwiki.net/images/b/b8/BernhardGschaider-OFW10_pyFoamPrepareCase.pdf
- Improved but without cats https://bit.ly/pyFPrepNoCats or Alternate URL https://openfoamwiki.net/images/9/97/BernhardGschaider-OFW13_pyFoamPrepareCase.pdf
pyFoamPlotRunner.py
Starting the simulation with residual plots by pyFoamPlotRunner.py:
pyFoamPlotRunner.py --clear --progress --auto --hardcopy --prefix=firstRun auto

pyFoamPlotWatcher.py
Looking at the curves again: "replay" the simulation process parameters but not re-run the simulation by pyFoamPlotWatcher.py:
pyFoamPlotWatcher.py --with-all --hardcopy --prefix=firstRunWatch PyFoamRunner.buoyantPimpleFoam.logfile
这个命令会复现计算过程中的残差曲线、库朗数等曲线图。
pyFoamPVSnapshot.py (暂未学会如何使用)
pyFoamPVSnapshot.py: creates a visualization state file:

pyFoamPVSnapshot.py . --state=hotWithStreamlines.pvsm --time=200 --latest
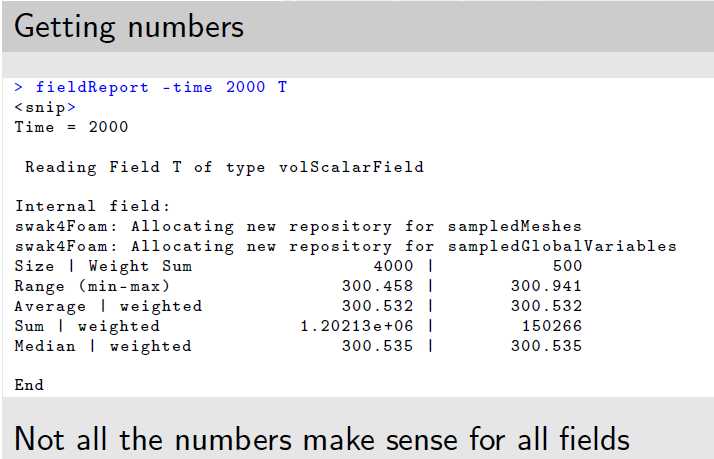
快速获取场数据的统计分布fieldReport
fieldReport -time 2000 T
fieldReport -time 0: -doBoundary -csvName numbers T #将结果导出到csv文件
ls *csv #查看导出的csv文件名
cat numbers_T_region0.csv #查看其中的数据

清理不必要的结果 pyFoamClearCase.py
pyFoamClearCase.py --verbose-clear --keep-last .
清理PyFoam生成的文件
功能:
- 删除
["PyFoamState.CurrentTime", "PyFoamState.LogDir", "PyFoamState.TheState", "PyFoamServer.info"]中的文件。 - 将
["PyFoamState.StartedAt", "PyFoamState.LastOutputSeen", "PyFoamHistory"]文件整理到pyFoamRecords文件中,并删除原文件。 - 如果原来已经存在
pyFoamRecords文件,则替换原文件中的"PyFoamState.StartedAt和PyFoamState.LastOutputSeen, 与原文件中的PyFoamHistory合并。
import os
import json
cwd = os.getcwd()
print("Current working directory: {0}".format(cwd))
os.chdir(cwd)
for file in ["PyFoamState.CurrentTime", "PyFoamState.LogDir",
"PyFoamState.TheState", "PyFoamServer.info"]:
try:
# delete file
os.remove(file)
print("Deleted file: {0}".format(file))
except OSError:
print("File not found: {0}".format(file))
pass
if os.path.isfile("PyFoamRecords") and os.stat("PyFoamRecords").st_size > 0:
with open("PyFoamRecords", "r") as f:
pyFoamRecords = json.load(f)
else:
pyFoamRecords = {"PyFoamState.StartedAt": "",
"PyFoamState.LastOutputSeen": "",
"PyFoamHistory": []
}
for file in ["PyFoamState.StartedAt", "PyFoamState.LastOutputSeen",
"PyFoamHistory"]:
try:
# read file
with open(file, "r") as f:
if file in ["PyFoamState.StartedAt", "PyFoamState.LastOutputSeen"]:
pyFoamRecords[file] = f.read()
else:
lines = [line.replace(" by by in ubuntu :Application", "")
for line in f.read().splitlines()]
pyFoamRecords[file] += lines
# delete file
os.remove(file)
print("Deleted file: {0}".format(file))
except OSError:
print("File not found: {0}".format(file))
pass
# save records to file pretty printed
with open("PyFoamRecords", "w") as f:
json.dump(pyFoamRecords, f, indent=4, sort_keys=False)
print("Saved file: PyFoamRecords")
解析PyFoam的log文件
import re
import numpy as np
import pandas as pd
# load log file "PyFoamRunner.mpirun.logfile"
logfile = open("PyFoamRunner.mpirun.logfile", "r")
# read log file line by line
timeStep = []
excutionTime = []
clockTime = []
residual_initial = []
residual_final = []
continuityGlobal = []
continuityCumulative = []
for line in logfile:
if re.search("Time = ", line):
# split line at "Time = "
splitline = line.split("Time = ")
# split second part at "\n"
splitline = splitline[1].split("\n")
# print time
if len(splitline) > 1 and splitline[1] == "":
print("--------------------")
time = splitline[0]
print("Time = " + time)
timeStep.append(time)
if re.search("ExecutionTime = ", line):
# split line at "ExecutionTime = "
splitline = line.split("ExecutionTime = ")
# split second part at "s"
splitline = splitline[1].split(" s ClockTime")
# print time
print("ExecutionTime = " + splitline[0])
excutionTime.append(splitline[0])
if re.search("ClockTime = ", line):
# split line at "ClockTime = "
splitline = line.split("ClockTime = ")
# split second part at "s"
splitline = splitline[1].split(" s")
# print time
print("ClockTime = " + splitline[0])
clockTime.append(splitline[0])
if re.search("Initial residual = ", line):
# split line at "Residual initial"
splitline = line.split("Initial residual = ")
# split second part at "final"
splitline = splitline[1].split(", Final")
# print time
print("Residual initial (p) = " + splitline[0])
residual_initial.append(splitline[0])
if re.search("Final residual = ", line):
splitline = line.split("Final residual = ")
splitline = splitline[1].split(", No Iterations")
print("Residual final (p) = " + splitline[0])
residual_final.append(splitline[0])
if re.search("time step continuity errors", line):
splitline = line.split("global = ") # first split
splitline = splitline[1].split(", cumulative = ") # second split
continuityGlobal.append(splitline[0])
continuityCumulative.append(splitline[1])
print("Continuity errors (global) = " + splitline[0])
print("Continuity errors (cumulative) = " + splitline[1])
# close log file
logfile.close()
# create array
columns = ["TimeStep", "ExecutionTime", "ClockTime", "Residual_initial", "Residual_Final",
"ContinuityGlobal", "ContinuityCumulative"]
# create empty array
data = np.full((len(timeStep) -1, len(columns)), -1.0)
# fill data array
data[:, 0] = np.array(timeStep[:-1], dtype=float)
data[:, 1] = np.array(excutionTime, dtype=float)
data[:, 2] = np.array(clockTime, dtype=float)
data[:, 3] = np.array(residual_initial, dtype=float)
data[:, 4] = np.array(residual_final, dtype=float)
data[:, 5] = np.array(continuityGlobal, dtype=float)
data[:, 6] = np.array(continuityCumulative, dtype=float)
# create a data frame from array and columns
df = pd.DataFrame(data, columns=columns)
df.to_csv("PyFoamRunner.mpirun.csv", index=False)
第一次修订: 2023/11/27 增加《清理
PyFoam生成的文件》和《解析PyFoam的log文件》代码
Comments NOTHING