1 Load the image sequence in FIJI/ImageJ
- Select
File$\rightarrow$import$\rightarrow$Image Sequence...
- Find the directory where the image sequence is using
Browse
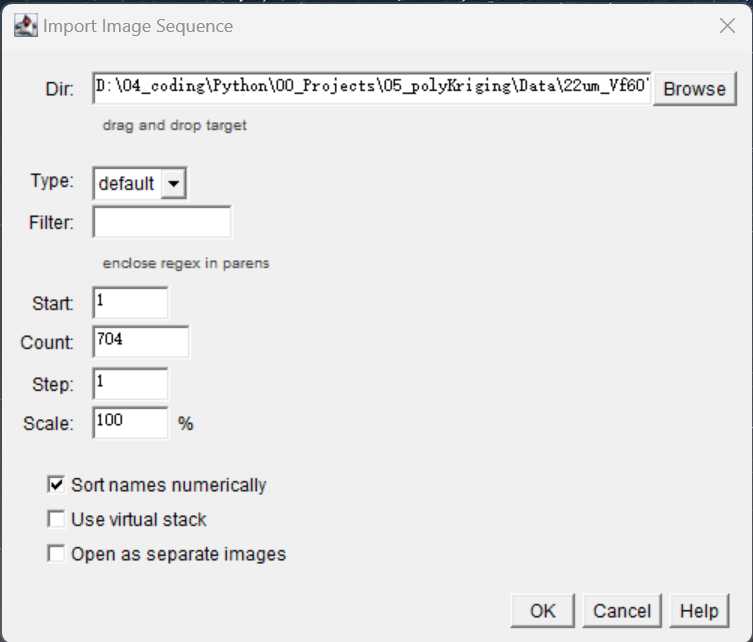
- Click
OKto load the image sequence - 3D viewer for image sequence
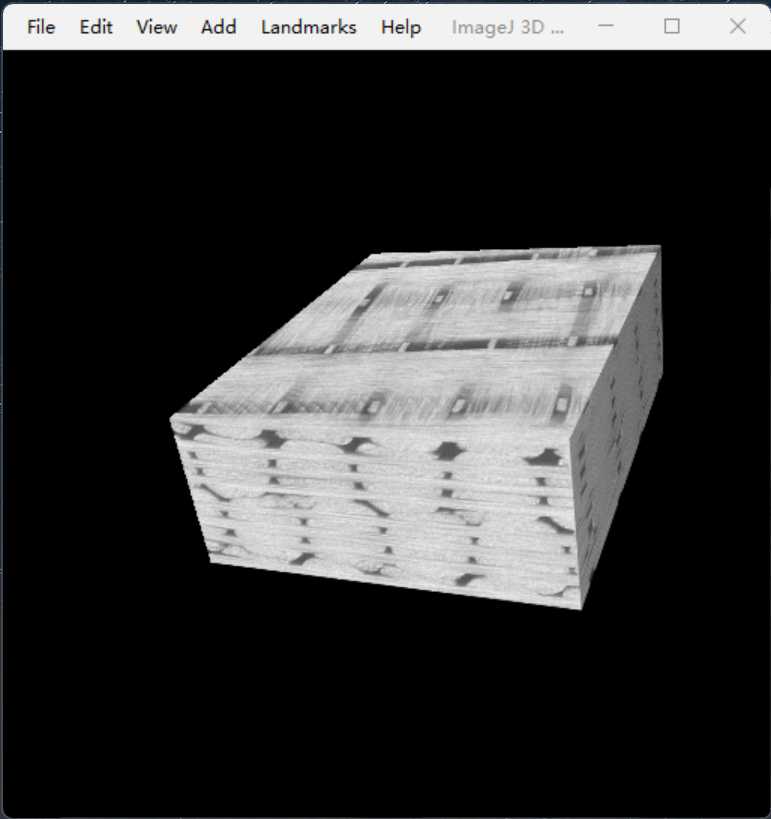
Select Plugins $\rightarrow$3D viewer $\rightarrow$OK. Wait for a while you will see the 3D view of the image sequence as below:
2 Image transformation between warp and weft direction
- load the image sequence oriented in the weft direction into
ImageJ;
-
Reslice the images as below to show the warp tows and binders;
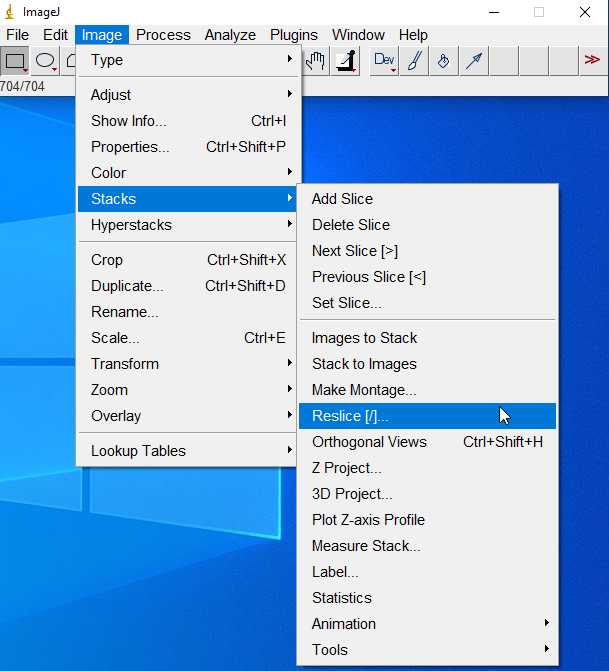
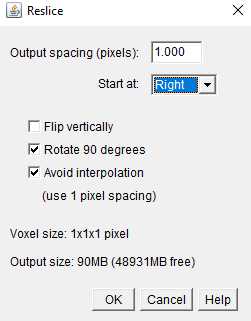
You should get:

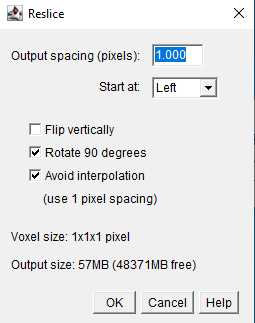
- Recover to the original weft view:
3 Manual selection of ROI
ROI: Region of Interest
- A label is assigned to each fiber tow. In the case of warp tows, for instance, the labels are assigned as below:

Let's use Tow 8 to show the procedure of manual segmentation.
4 Import existing selections:
- Load the image sequence which the ROI information belonging to.
- Drag and put the ROI file (
.zipfile containing multi.roifiles)
If the ROI information was stored in csv files, the following code to can be used in imageJ (save the code as
xxx.ijmfile) to import.
csv to ROI
run("Select None");//Remove all the selections roiManager("reset");//Reset the ROI manager dir_ROI = getDirectory("Choose a Directory to import") list = getFileList(dir_ROI); image_roi = getTitle(); for(i = 0; i < list.length; i++){ Table.open(dir_ROI+'Long_0_F_'+ 4*i+1 +'.csv'); xpoints = Table.getColumn("x"); ypoints = Table.getColumn("y"); zpoints = Table.get("z", 2); print(zpoints); selectWindow(image_roi); setSlice(zpoints); makeSelection("polygon", xpoints, ypoints); roi_name = "0"+zpoints; Roi.setName(roi_name); roiManager("Add"); roiManager("select", i) RoiManager.setPosition(zpoints); close(Table.title); }

5 Export the selections (ROI) to csv and .npz file
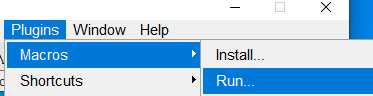
Then run the following code that stored in a xxxx.ijm file:
5.1 ROI to csv
ROI_output_csv.ijmcode for imageJ
//index for tow index/label
dir_open = getDirectory("Choose the directory of ROI files");
dir_saving = getDirectory("Choose a Directory to save");
for(index = 83; index < 84; index++){
dir_saving2 = dir_saving + "weft_" + index +"/";
roiManager("Open", dir_open + "weft_" + index + ".zip");
run("Clear Results");
n = roiManager('count');
for (i = 0; i < n; i++) {
run("Clear Results");
roiManager('select', i);
getSelectionCoordinates(x, y);
z=getSliceNumber();
for (j=0; j<x.length; j++) {
setResult("x", j, x[j]);
setResult("y", j, y[j]);
setResult("z", j, z);
}
setOption("ShowRowNumbers", true);
updateResults;
z=z-1; // The filenames start from 0 to be consistent with Python
saveAs("Results", dir_saving2 + 'weft_'+index + '_' + z + '.csv');}
roiManager("Deselect");
roiManager("Delete");
}
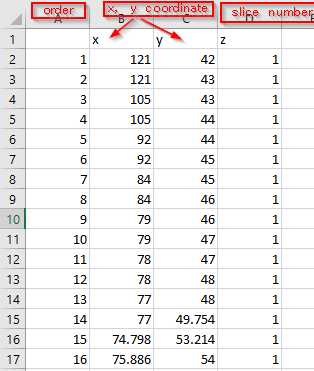
A single csv file contains the key points or pixel positions to describe a cross-section of a fiber tow in the following format:
Comments NOTHING