稀疏矩阵(英语:sparse matrix)指的是在数值分析中绝大多数数值为零的矩阵。反之,如果大部分元素都非零,则这个矩阵是稠密的(Dense)。
参考自:https://www.runoob.com/scipy/scipy-sparse-matrix.html ; http://liao.cpython.org/scipy03.html
在科学与工程领域中求解线性模型时经常出现大型的稀疏矩阵。第一反应是升级电脑配件升级内存条,但是不太可行。当涉及数百万行和/或数百列时,pandas DataFrames 并不适用,会出现memory error的问题。在做流动仿真时需要针对N个节点生成一个相关的N×N矩阵计算压力场,但是电脑对于元素存储量的大小有限制。32位python的限制是536870912(23170.475 × 23170.475)个元素。 64位python的限制是1152921504606846975 个元素。而且随着节点的增多,np.linalg.solve所需的时间也指数级增长。因此考虑只存储矩阵中的非零数值。
稀疏矩阵求解线性方程:
必须完整 from scipy.sparse.linalg import spsolve
spsolve(A, b)
求解稀疏线性系统Ax=b,其中b可以是向量也可以是矩阵。
https://docs.scipy.org/doc/scipy/reference/sparse.linalg.html
严格意义上讲ndarray数据类型应属数组而非矩阵,而matrix才是矩阵.稀疏矩阵是一个矩阵里有小于5%非0数据的矩阵可以视为稀疏矩阵,如果矩阵的总数据量较大,完成存储这个矩阵会有大量的0存储,浪费空间,所以对稀疏矩阵的存储有必要研究用少量的内存存储稀疏矩阵。其最主要的缺点是难以直观访问单个元素,需要指定索引单个查看或者M.todense()之后整体查看。
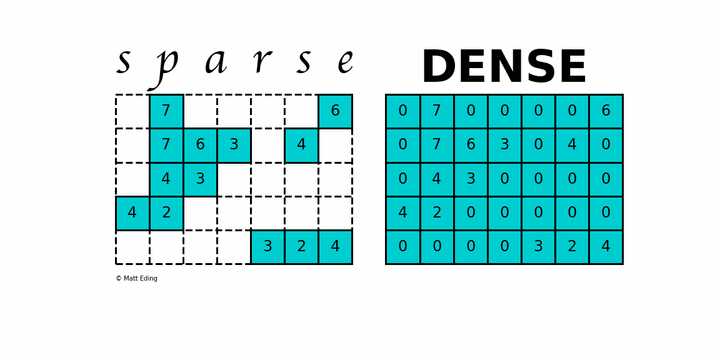
上图中左边就是一个稀疏矩阵,可以看到包含了很多 0 元素,右边是稠密的矩阵,大部分元素不是 0。看一个简单例子:

上述稀疏矩阵仅包含 9 个非零元素,另外包含 26 个零元。其稀疏度为 74%,密度为 26%。
SciPy 的 scipy.sparse 模块提供了处理稀疏矩阵的函数。
稀疏矩阵格式
- 高效修改 - 使用 DOK、LIL 或 COO。 这些通常用于构建矩阵。
- 有效的访问和矩阵操作 - 使用 CSR 或 CSC
1. coo_matrix
coo_matrix是最简单的稀疏矩阵存储方式(Coordinate list (COO)),采用三元组(row, col, data)(或称为ijv format)的形式来存储矩阵中非零元素的信息。在实际使用中,一般coo_matrix用来创建矩阵,但是因为coo_matrix无法对矩阵的元素进行增删改操作;创建成功一般转化成其他格式的稀疏矩阵(如csr_matrix、csc_matrix)进行转置、矩阵乘法等操作。

coo_matrix可以通过四种方式实例化:
- coo_matrix(D), D代表密集矩阵;
- coo_matrix(S), S代表其他类型稀疏矩阵;
- coo_matrix((M, N), [dtype])构建一个shape为M*N的空矩阵,默认数据类型是d;
- (row, col, data)三元组初始化。
实例:
三元组triplet format的形式创建coo_matrix并转化为密集矩阵的两种方法
import numpy as np
from scipy.sparse import coo_matrix
_row = np.array([0, 3, 1, 0])
_col = np.array([0, 3, 1, 2])
_data = np.array([4, 5, 7, 9])
coo = coo_matrix((_data, (_row, _col)), shape=(4, 4), dtype=np.int32)
coo.todense() # 通过toarray方法转化成密集矩阵(numpy.matrix)
matrix([[4, 0, 9, 0],
[0, 7, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 5]])
coo.toarray() # 通过toarray方法转化成密集矩阵(numpy.ndarray)
array([[4, 0, 9, 0],
[0, 7, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 5]])
coo_matrix对象有以下属性:
print('矩阵中元素的数据类型:',coo.dtype)
print('获取矩阵的shape:',coo.shape)
print('获取矩阵的维度:',coo.ndim)
print('存储值的个数,包括显示声明的零元素(注意):',coo.nnz)
output:
矩阵中元素的数据类型: int32
获取矩阵的shape: (4, 4)
获取矩阵的维度: 2
存储值的个数,包括显示声明的零元素(注意): 4
print('稀疏矩阵存储的值,是一个1维数组:',coo.data)
print('与`data`同等长度的一维数组,表征`data`中每个元素的行号:',coo.row)
print('与`data`同等长度的一维数组,表征`data`中每个元素的列号:',coo.col)
output:
稀疏矩阵存储的值,是一个1维数组: [4 5 7 9]
与`data`同等长度的一维数组,表征`data`中每个元素的行号: [0 3 1 0]
与`data`同等长度的一维数组,表征`data`中每个元素的列号: [0 3 1 2]
在实际应用中,coo_matrix矩阵文件通常存成以下形式,表示稀疏矩阵是coo_matrix(coordinate),由13885行1列组成,共有949个元素值为非零,数据类型为整形。

mmread()用于读取稀疏矩阵,mmwrite()用于写入稀疏矩阵,mminfo()用于查看稀疏矩阵文件元信息。(这三个函数的操作不仅仅限于coo_matrix)
from scipy.io import mmread, mmwrite, mminfo
HERE = dirname(__file__)
coo_mtx_path = join(HERE, 'data/matrix.mtx')
coo_mtx = mmread(coo_mtx_path)
print(mminfo(coo_mtx_path))
# (13885, 1, 949, 'coordinate', 'integer', 'general')
# (rows, cols, entries, format, field, symmetry)
mmwrite(join(HERE, 'data/saved_mtx.mtx'), coo_mtx)
coo_matrix的优点:
- 有利于稀疏格式之间的快速转换(tobsr()、tocsr()、to_csc()、to_dia()、to_dok()、to_lil())
- 允许又重复项(格式转换的时候自动相加)
- 能与CSR / CSC格式的快速转换
coo_matrix的缺点:
- 不能直接进行算术运算
2. csc_matrix 和 csr_matrix矩阵
- CSC - 压缩稀疏列(Compressed Sparse Column),按列压缩。
- CSR - 压缩稀疏行(Compressed Sparse Row),即按行压缩的稀疏矩阵存储方式。
2.1 csr_matrix
我们可以通过 scipy.sparse.csr_matrix() 函数传递数组来创建一个 CSR 矩阵。由三个一维数组indptr, indices, data组成。这种格式要求矩阵元按行顺序存储,每一行中的元素可以乱序存储。那么对于每一行就只需要用一个指针表示该行元素的起始位置即可。indptr存储每一行数据元素的起始位置,indices这是存储每行中数据的列号,与data中的元素一一对应。
The compressed row storage (CRS) format puts the subsequent nonzeros of the matrix rows in contiguous memory locations. Assuming we have a nonsymmetric sparse matrix AAA, we create three vectors: one for floating point numbers (val) and the other two for integers (col_ind, row_ptr). The val vector stores the values of the nonzero elements of the matrix AAA as they are traversed in a row-wise fashion. The col_ind vector stores the column indexes of the elements in the val vector. That is, if val(k)\=ai,j\operatorname{val}(\mathrm{k})=a_{i, j}val(k)\=ai,j, then col_ind (k)\=j(\mathrm{k})=j(k)\=j. The row_ptr vector stores the locations in the val vector that start a row; that is, if val(k)\=ai,j\operatorname{val}(\mathrm{k})=a_{i, j}val(k)\=ai,j, then row_ptr (i)≤k<(i) \leq k<(i)≤k< row_ptr (i+1)(i+1)(i+1). By convention, we define row_ptr (n+1)\=nnz+1(\mathrm{n}+1)=n n z+1(n+1)\=nnz+1, where nnzn n znnz is the number of nonzeros in the matrix AAA. The storage savings for this approach is significant. Instead of storing n2n^2n2 elements, we need only 2nnz+n+12 n n z+n+12nnz+n+1 storage locations.
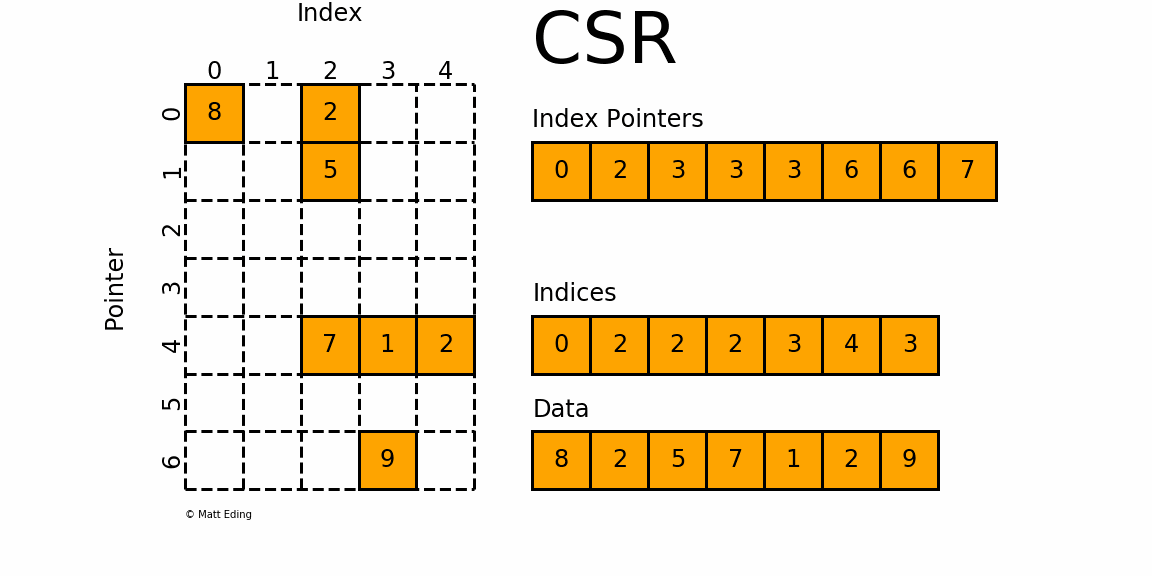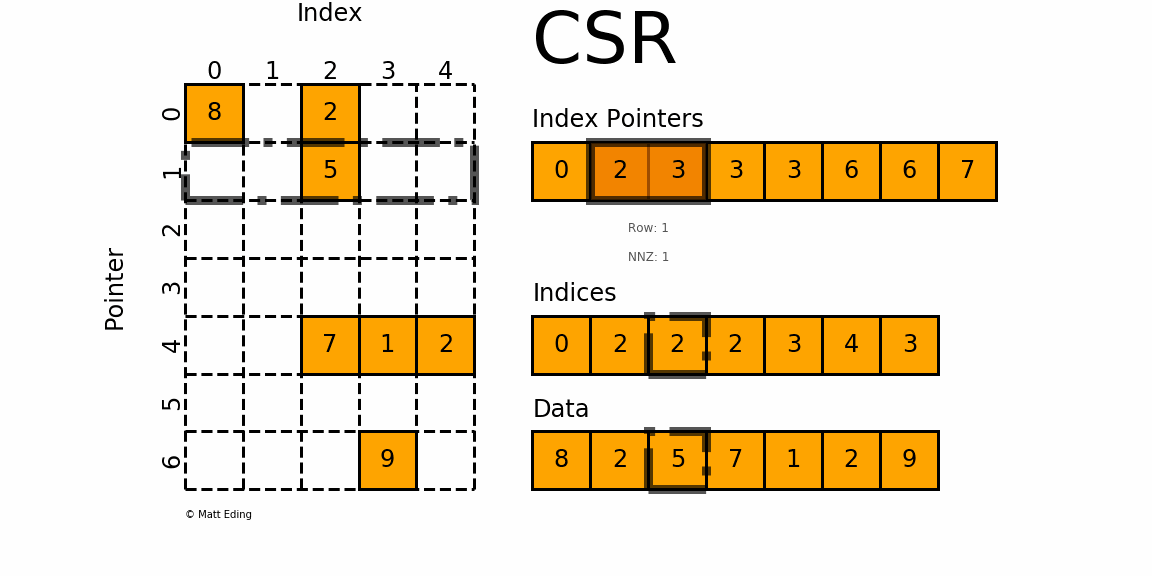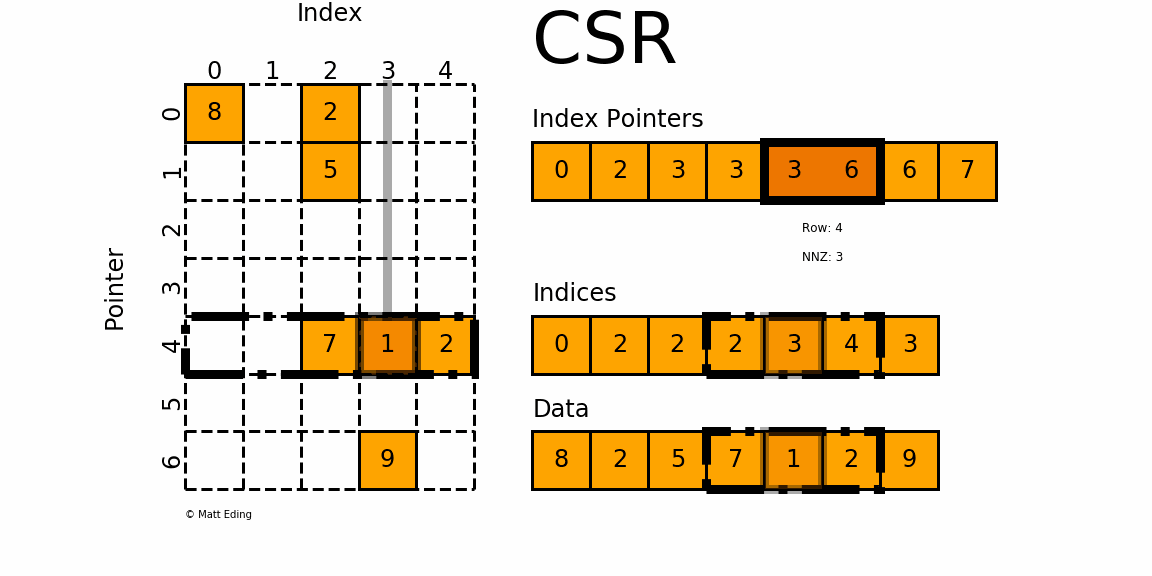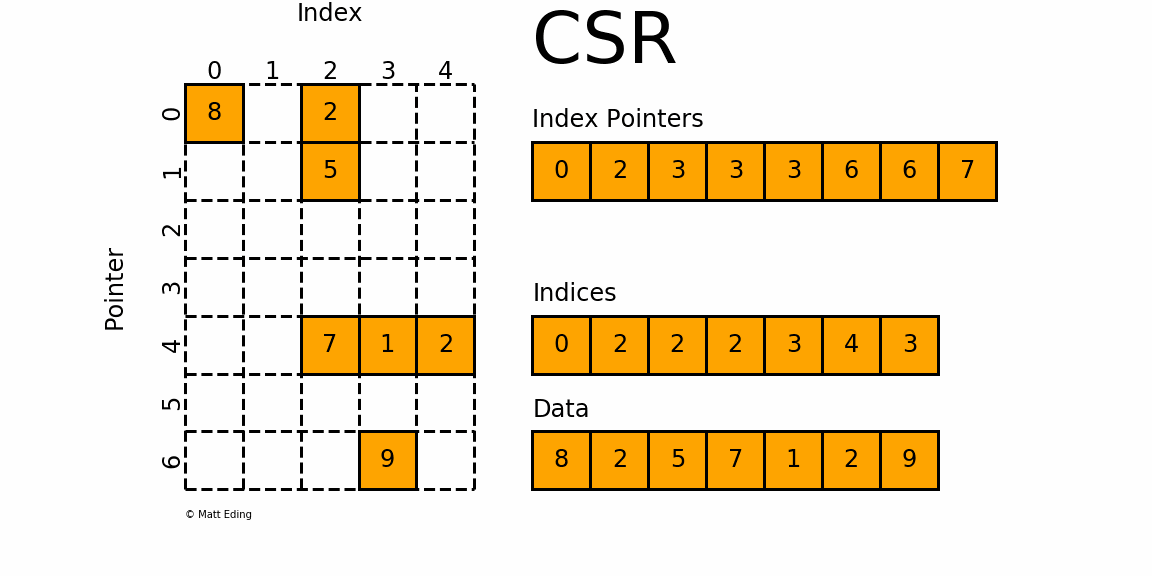
如此图:
矩阵一共有7个非零元素,所以value array=[8,2,5,7,1,2,9]=Data,长度为7,按照行的次序排列;
列索引数组 column index array = indices 存储矩阵中元素的列索引。8\~0、2\~2、5\~2、7\~2、1\~3、2\~4、9\~3,因此为[0,2,2,2,3,4,3]
行索引数组 row index array = indexpointer 为该矩阵所有之前所有行不包括当前行中非零值的累计计数。row_index_array [j] 编码第 j 行上方非零的总数。 最后一个元素表示原始数组中所有非零元素的数量。 长度为 m + 1; 其中 m 定义为原始矩阵中的行数。例如第一行前一行不存在元素,所以为0,第二行的值为第一行中非零元素的个数为2(8和2),第5行为前4行中所有非零元素的个数(2(8和2)+1(5)+0+0)=3,依次类推。
csr_matrix可用于各种算术运算:它支持加法,减法,乘法,除法和矩阵幂,线性代数等操作。其有五种实例化方法:
- 通过密集矩阵构建;
- 通过其他类型稀疏矩阵转化;
- 构建一定shape的空矩阵;
- 通过(row, col, data)构建矩阵;
- csr_matrix((data, indices, indptr), [shape=(M, N)])
(https://blog.csdn.net/jeffery0207/article/details/100064602)
import numpy as np
from scipy.sparse import csr_matrix
A = np.array([0, 0, 0, 0, 0, 1, 1, 0, 2])
print(csr_matrix(A))
输出:
(0, 5) 1
(0, 6) 1
(0, 8) 2
结果解析:
- 第一行:在矩阵第一行(索引值 0 )第六(索引值 5 )个位置有一个数值 1。
- 第二行:在矩阵第一行(索引值 0 )第七(索引值 6 )个位置有一个数值 1。
- 第三行:在矩阵第一行(索引值 0 )第九(索引值 8 )个位置有一个数值 2。
>>> import numpy as np
>>> from scipy.sparse import csr_matrix
>>> indptr = np.array([0, 2, 3, 6])
>>> indices = np.array([0, 2, 2, 0, 1, 2])
>>> data = np.array([1, 2, 3, 4, 5, 6])
>>> csr = csr_matrix((data, indices, indptr), shape=(3, 3)).toarray()
array([[1, 0, 2],
[0, 0, 3],
[4, 5, 6]])
csr_matrix同样有很多方法,包括tobytes(),tolist(), tofile(),tostring(),csr_matrix对象属性前五个同coo_matrix,另外还有属性如下:
import numpy as np
from scipy.sparse import csr_matrix
indptr = np.array([0, 2, 3, 6])
indices = np.array([0, 2, 2, 0, 1, 2])
data = np.array([1, 2, 3, 4, 5, 6])
csr = csr_matrix((data, indices, indptr), shape=(3, 3))
print('密集矩阵转化的数组 csr.toarray():\n',csr.toarray())
print('每个元素对应的列号 csr.indices:',csr.indices)
print('矩阵每一行对应的所有之前行累计非零元素值 csr.indptr:',csr.indptr)
print('矩阵中的所有定义元素 csr.data:',csr.data)
print('判断每一行的indices列号是否是有序的,返回bool值:',csr.has_sorted_indices)
输出:
密集矩阵转化的数组 csr.toarray():
[[1 0 2]
[0 0 3]
[4 5 6]]
每个元素对应的列号 csr.indices: [0 2 2 0 1 2]
矩阵每一行对应的所有之前行累计非零元素值 csr.indptr: [0 2 3 6]
矩阵中的所有定义元素 csr.data: [1 2 3 4 5 6]
判断每一行的indices列号是否是有序的,返回bool值: True
csr_matrix的优点:
高效的算术运算CSR + CSR,CSR * CSR等
高效的行切片
快速矩阵运算
csr_matrix的缺点:
列切片操作比较慢(考虑csc_matrix)
稀疏结构的转换比较慢(考虑lil_matrix或doc_matrix)
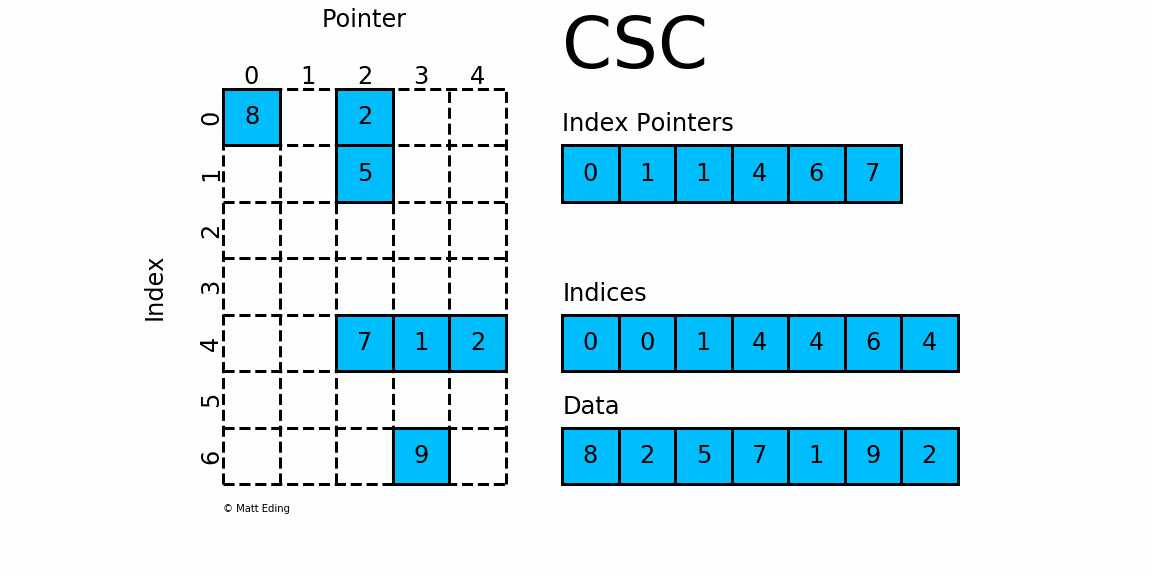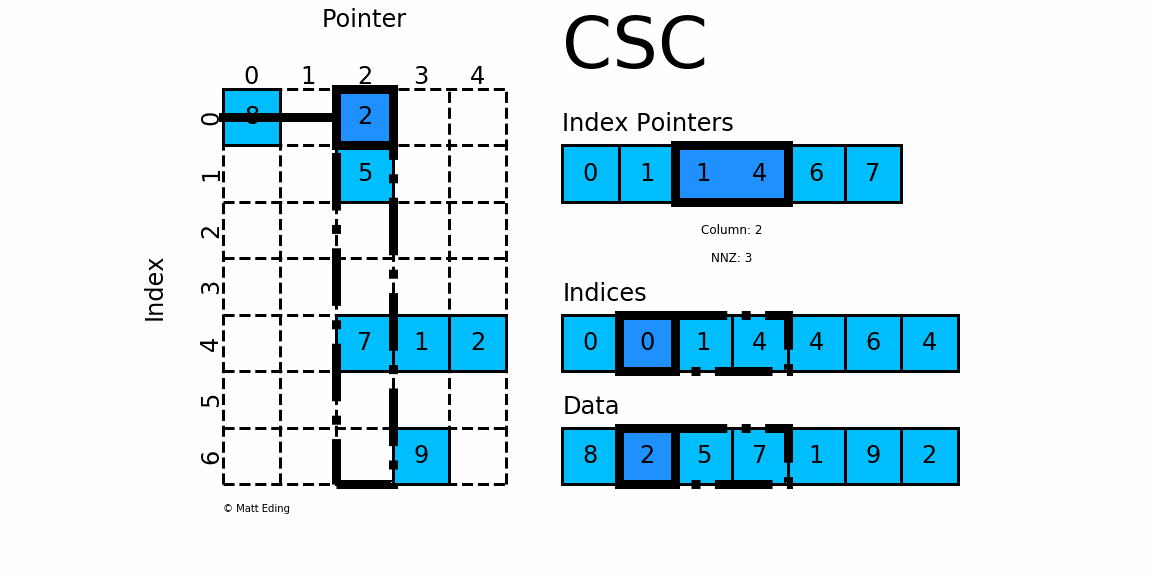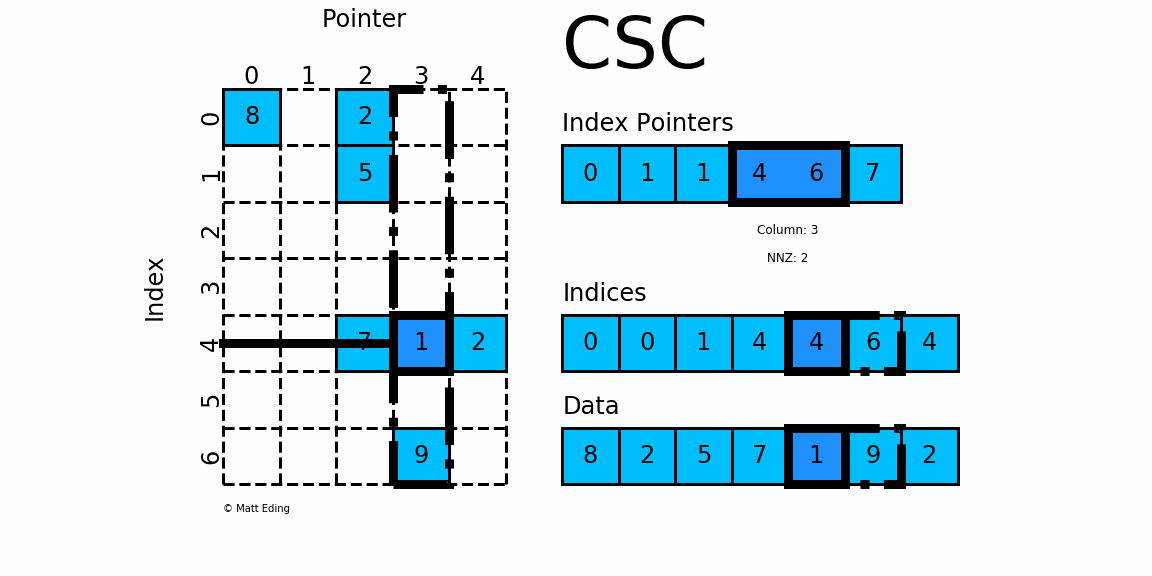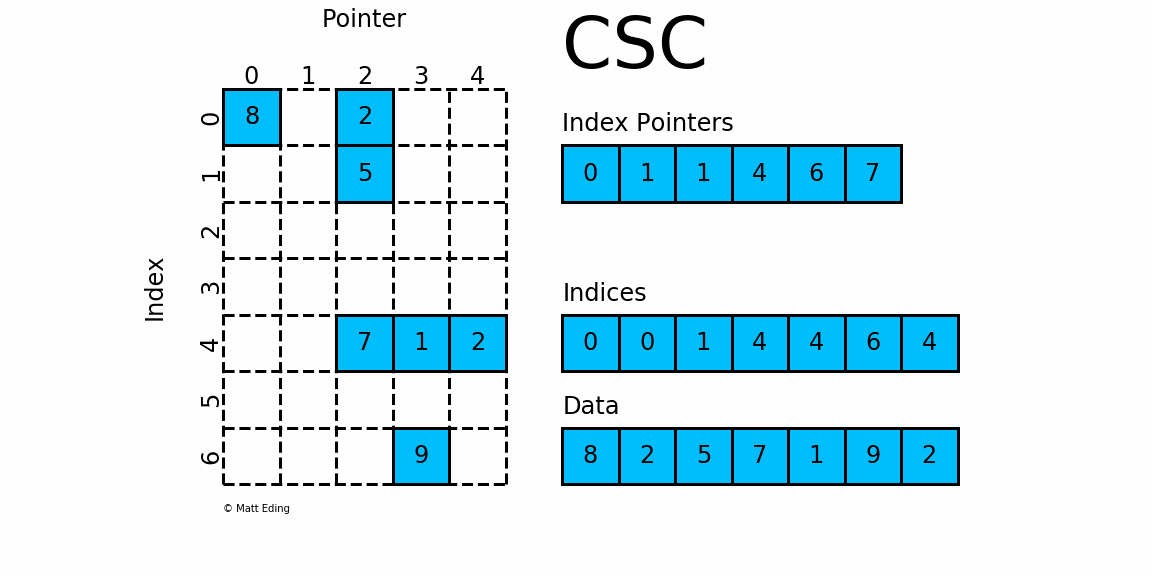
2.2 csc_matrix
按列压缩的稀疏矩阵存储方式,同样由三个一维数组indptr, indices, data组成.
2.3 lil_matrix
List of Lists format,又称为Row-based linked list sparse matrix。它使用两个嵌套列表存储稀疏矩阵:data保存每行中的非零元素的值,rows保存每行非零元素所在的列号(列号是顺序排序的)。这种格式很适合逐个添加元素,并且能快速获取行相关的数据。其初始化方式同coo_matrix初始化的前三种方式:通过密集矩阵构建、通过其他矩阵转化以及构建一个一定shape的空矩阵。
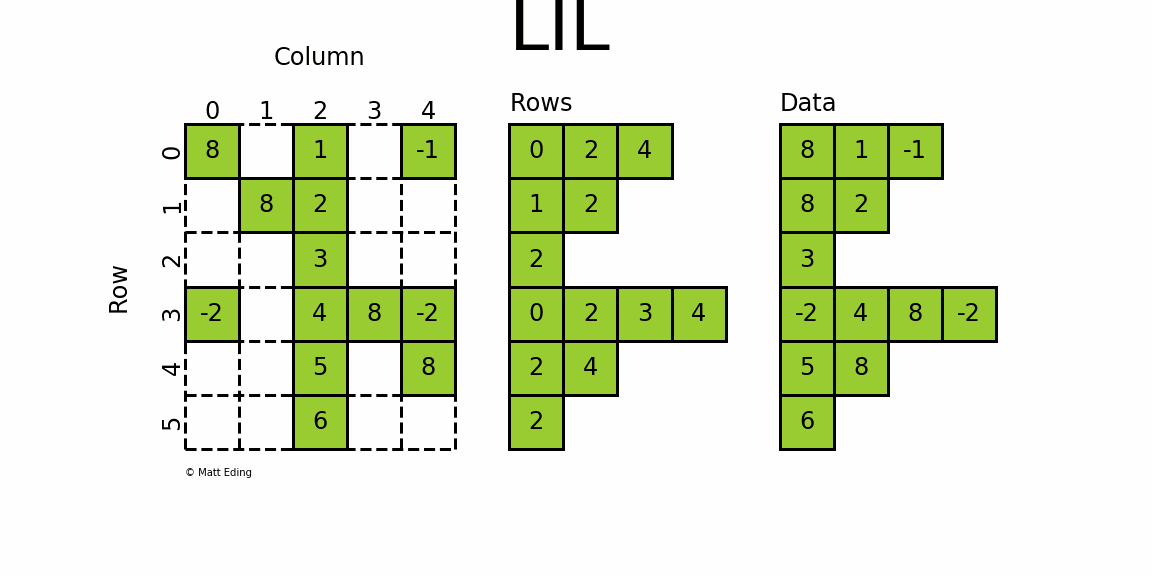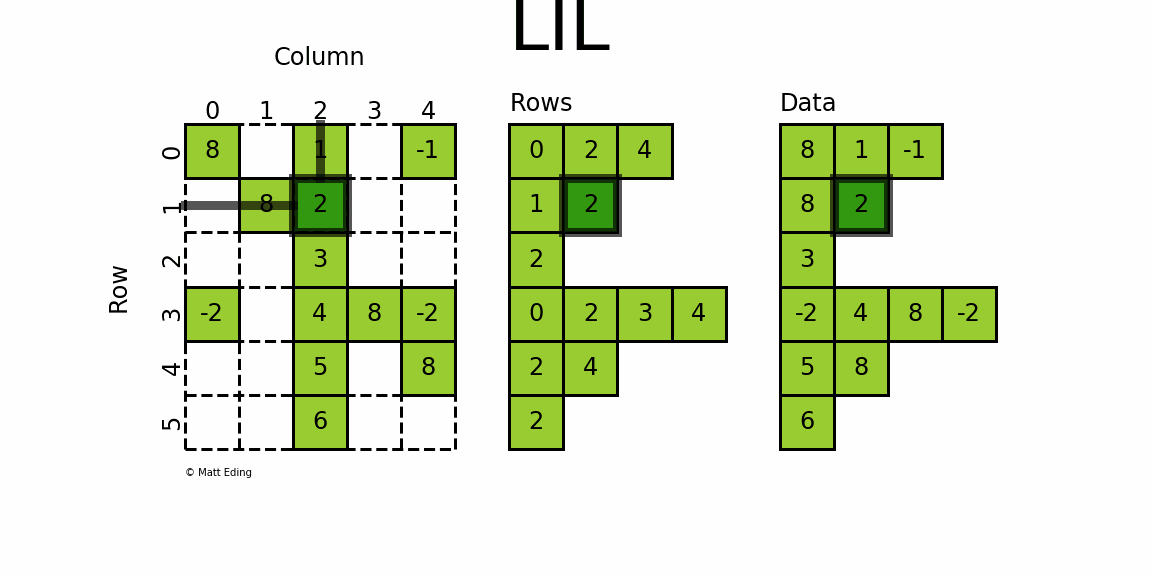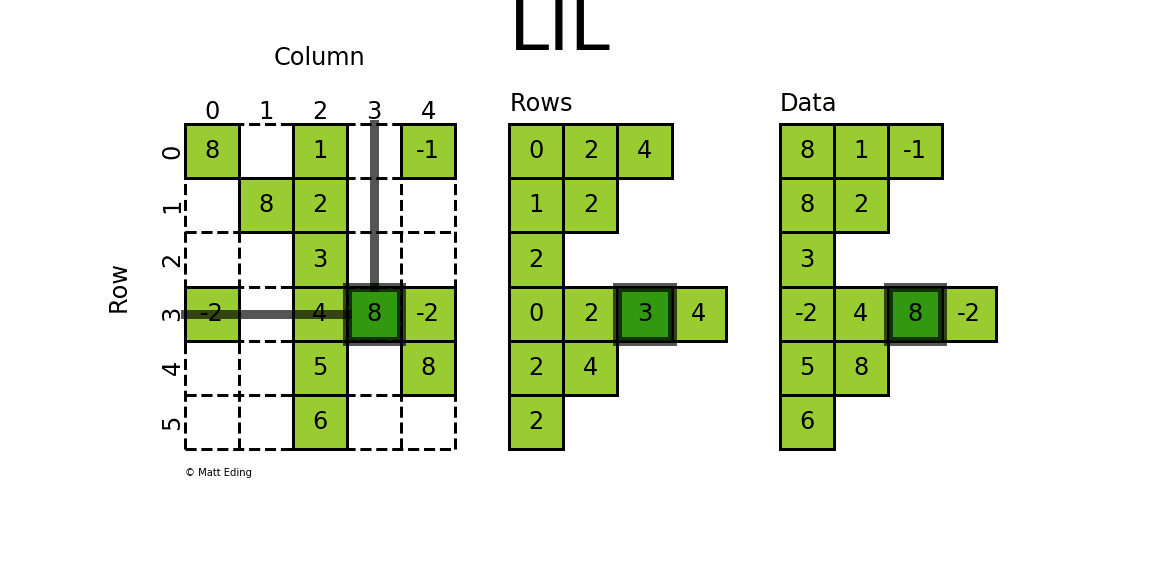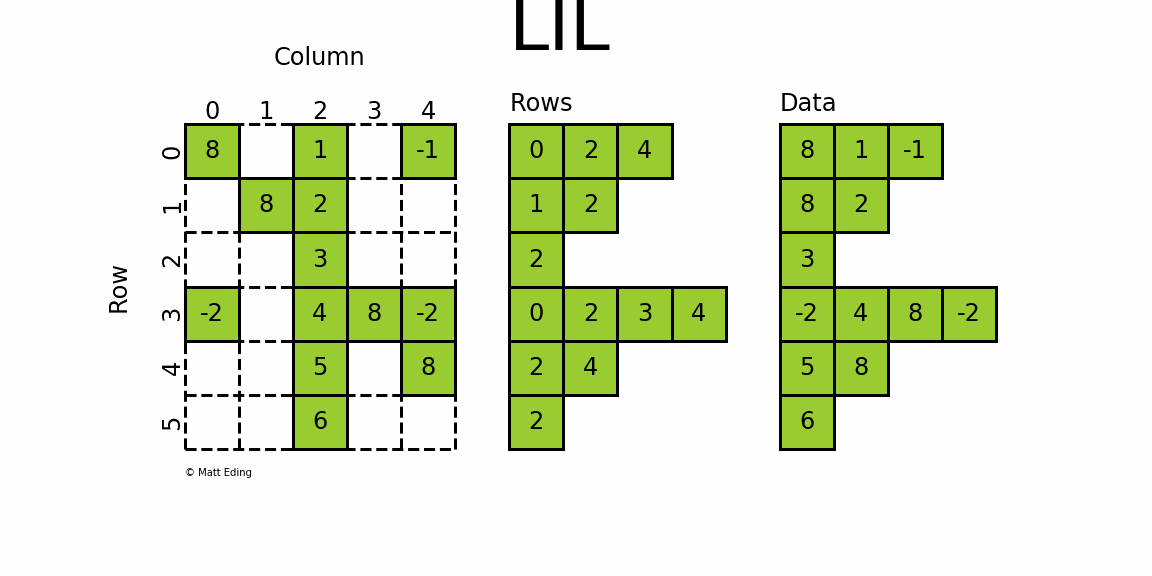
lil_matrix可用于算术运算:支持加法,减法,乘法,除法和矩阵幂。其属性前五个同coo_matrix,另外还有rows属性,是一个嵌套List,表示矩阵每行中非零元素的列号。因此非常适合液体成型模拟,因为根据节点构建矩阵,方便通过行列修改元素。LIL matrix本身的设计是用来方便快捷构建稀疏矩阵实例,而算术运算、矩阵运算则转化成CSC、CSR格式再进行,构建大型的稀疏矩阵还是推荐使用COO格式。
lil_matrix优点:
支持灵活的切片操作行切片操作效率高,列切片效率低;稀疏矩阵格式之间的转化很高效(tobsr()、tocsr()、to_csc()、to_dia()、to_dok()、to_lil())
lil_matrix缺点:
加法操作效率低 (consider CSR or CSC);列切片效率低(consider CSC);矩阵乘法效率低 (consider CSR or CSC)
other matrix
不常用,不多做介绍
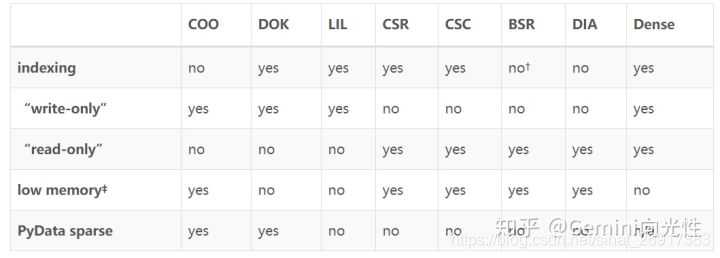
参考:https://zhuanlan.zhihu.com/p/456904535
scipy.sparse
| 方法 | 用途 |
|---|---|
identity(n[, dtype, format]) |
生成稀疏单位矩阵 |
kron(A, B[, format]) |
sparse matrices A 和 B的克罗内克积 |
kronsum(A, B[, format]) |
sparse matrices A 和 B的克罗内克和 |
diags(diagonals[, offsets, shape, format, dtype]) |
构建稀疏对角阵 |
spdiags(data, diags, m, n[, format]) |
构建稀疏对角阵,同上,但不可指定shape |
block_diag(mats[, format, dtype]) |
mats为iterable, 包含多个矩阵,根据mats构建块对角稀疏矩阵。 |
tril(A[, k, format]) |
以稀疏格式返回矩阵的下三角部分 |
triu(A[, k, format]) |
以稀疏格式返回矩阵的上三角部分 |
bmat(blocks[, format, dtype]) |
从稀疏子块构建稀疏矩阵 |
hstack(blocks[, format, dtype]) |
水平堆叠稀疏矩阵(column wise) |
vstack(blocks[, format, dtype]) |
垂直堆叠稀疏矩阵 (row wise) |
rand(m, n[, density, format, dtype, …]) |
使用均匀分布的值生成给定形状和密度的稀疏矩阵 |
random(m, n[, density, format, dtype, …]) |
使用随机分布的值生成给定形状和密度的稀疏矩阵 |
eye(m[, n, k, dtype, format]) |
生成稀疏单位对角阵(默认DIAgonal format) |
data 属性查看存储的数据(不含 0 元素):
import numpy as np
from scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
print(csr_matrix(arr).data)
以上代码输出结果为:
[1 1 2]
使用 count_nonzero() 方法计算非 0 元素的总数:
import numpy as np
from scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
print(csr_matrix(arr).count_nonzero())
以上代码输出结果为:
3
使用 eliminate_zeros() 方法删除矩阵中 0 元素:
import numpy as np
from scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
mat = csr_matrix(arr)
mat.eliminate_zeros()
print(mat)
以上代码输出结果为:
(1, 2) 1
(2, 0) 1
(2, 2) 2
使用 sum_duplicates() 方法来删除重复项:
import numpy as np
from scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
mat = csr_matrix(arr)
print(mat)
mat.sum_duplicates()
print(mat.todense())
以上代码输出结果为:
(1, 2) 1
(2, 0) 1
(2, 2) 2
[[0 0 0]
[0 0 1]
[1 0 2]]
csr 转换为 csc 使用 tocsc() 方法:
第一个索引由row变为column
import numpy as np
from scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
csr = csr_matrix(arr)
csc = csr.tocsc()
print('csr:',csr,'\n',csr.todense())
print('csc:',csc,'\n',csc.todense())
输出
csr:
(1, 2) 1
(2, 0) 1
(2, 2) 2
[[0 0 0]
[0 0 1]
[1 0 2]]
csc:
(2, 0) 1
(1, 2) 1
(2, 2) 2
[[0 0 0]
[0 0 1]
[1 0 2]]
Comments NOTHING