一. Numpy 方法
import numpy as np
'''二维数组的保存和读取'''
Matrix=np.array([[1,2,3],[4,5,6],[7,8,9]])
Matrix.shape
[out]:(3, 3)
1.1 np.savetxt()/np.loadtxt() or np.genfromtxt()
四个参数依次为文件名、数组、数据类型(浮点型)、分隔符(逗号)。只能存储一维和二维数组.
文件名后缀:.dat/.csv/.txt
np.savetxt("H:/a.txt", Matrix, fmt = '%f', delimiter = ',')
M=np.loadtxt("H:/a.txt", delimiter = ',',dtype=np.float32)
M
[out]:
array([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]], dtype=float32)
np.savetxt("H:/a2.csv", Matrix, fmt = '%f', delimiter = ',')
M1=np.genfromtxt("H:/a2.csv", delimiter = ',',dtype=np.float32)
M
[out]:array([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]], dtype=float32)
1.2 np.save()/np.load()
np.save和np.load是读写磁盘数组数据的两个主要函数。
默认情况下,数组以未压缩的原始二进制格式保存在扩展名为npy的文件中
np.save("H:/b.npy",Matrix)
M=np.load("H:/b.npy")
M
[out]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
1.3 .tofile()/np.fromfile()
不推荐。只能将数组保存为二进制文件,文件后缀名没有固定要求。
np.fromfile 需要手动指定读出来的数据的的dtype,如果指定的格式与保存时的不一致,则读出来的就是错误的数据。
tofile函数不能保存当前数据的行列信息,不管数组的排列顺序是C语言格式的还是Fortran语言格式,统一使用C语言格式输出。
因此使用 np.fromfile 读出来的数据是一维数组,需要利用reshape指定行列信息。
Matrix.tofile("H:/c.bin")
M1=np.fromfile("H:/c.bin",dtype=np.int32)
M2=np.fromfile("H:/c.bin",dtype=np.int64)
M3=np.fromfile("H:/c.bin",dtype=np.float32)
M4=np.fromfile("H:/c.bin",dtype=np.float64)
print(M1,M2,M3,M4)
[out]:
[1 2 3 4 5 6 7 8 9]
[ 8589934593 17179869187 25769803781 34359738375]
[1.4e-45 2.8e-45 4.2e-45 5.6e-45 7.0e-45 8.4e-45 9.8e-45 1.1e-44 1.3e-44] [4.24399158e-314 8.48798317e-314 1.27319747e-313 1.69759663e-313]
时间比较
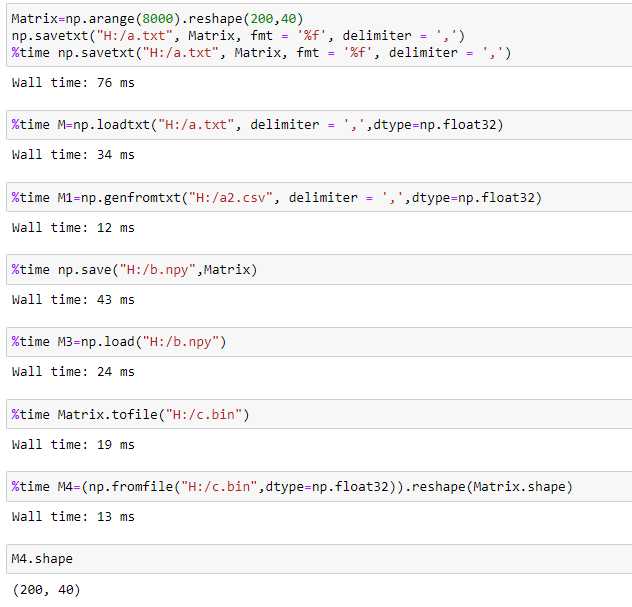
二. Python直接读取
读取大文件可能会出现memory error,内存溢出。大文件可以逐行读取,处理完这行,就可以把它抛弃。也可以一段一段读取大文件,实现一种缓存处理。每次读取一段文件,将这段文件放在缓存里,然后对这段处理。这会比一行一行快些。
2.1 read()
通过参数指定每次读取的大小长度,这样就避免了因为文件太大读取出问题。
while True:
block = f.read(1024)
if not block:
break
2.2 readline()
每次读取一行
while True:
line = f.readline()
if not line:
break
2.3 readlines()
读取全部的行,构成一个list,通过list来对文件进行处理,但是这种方式依然会造成MemoyError
for line in f.readlines():
2.4 linecache 只读取其中一行
import linecache
text=linecache.getline("H:/a.txt",1) #行数从1开始
%time text=linecache.getline("H:/a.txt",1)
text
[out]:
Wall time: 0 ns
Out[40]:
'0.000000,1.000000,2.000000,3.000000,4.000000,5.000000,6.000000,7.000000,8.000000,9.000000,10.000000,11.000000,12.000000,13.000000,14.000000,15.000000,16.000000,17.000000,18.000000,19.000000,20.000000,21.000000,22.000000,23.000000,24.000000,25.000000,26.000000,27.000000,28.000000,29.000000,30.000000,31.000000,32.000000,33.000000,34.000000,35.000000,36.000000,37.000000,38.000000,39.000000\n'
Comments NOTHING